Lec03:OS Organization and System Calls (Frans)
主要讨论4个话题:
- Isolation。隔离性是设计操作系统组织结构的驱动力。
- Kernel和User mode。这两种模式用来隔离操作系统内核和用户应用程序。
- System calls。系统调用是你的应用程序能够转换到内核执行的基本方法,这样你的用户态应用程序才能使用内核服务。
- 最后我们会看到所有的这些是如何以一种简单的方式在XV6中实现。
操作系统隔离性(isolation)和 防御性(Defensive)
- 操作系统隔离性
如果没有操作系统隔离性,会怎么样?
若应用程序直接与硬件交互:
后果:
- 恶意的应用程序可以一直占有硬件不释放,使其他应用程序无法执行
- 应用程序可能会访问不属于他的内存空间,破坏其他进程
所以我们需要一个操作系统来实现强隔离性
- 操作系统防御性
- 操作系统需要能够应对恶意的应用程序
后果:
- 应用程序无意或者恶意的向系统调用传入一些错误的参数导致操作系统崩溃,这样,操作系统会因为崩溃了拒绝为其他所有的应用程序提供服务
- 防止应用程序控制内核,控制所有的硬件资源
硬件对于强隔离的支持
- 硬件对于强隔离的支持包括了:user/kernle mode和Virtual memory
为了支持user/kernel mode,处理器会有两种操作模式,
第一种是user mode,第二种是kernel mode。
当运行在kernel mode时,CPU可以运行特定权限的指令(privileged instructions);
当运行在user mode时,CPU只能运行普通权限的指令(unprivileged instructions)
普通权限的指令都是一些你们熟悉的指令,例如将两个寄存器相加的指令ADD、将两个寄存器相减的指令SUB、跳转指令JRC、BRANCH指令等等。这些都是普通权限指令,所有的应用程序都允许执行这些指令。
特殊权限指令主要是一些直接操纵硬件的指令和设置保护的指令,例如设置page table寄存器、关闭时钟中断。在处理器上有各种各样的状态,操作系统会使用这些状态,但是只能通过特殊权限指令来变更这些状态。
当一个应用程序尝试执行一条特殊权限指令,但由于在user mode 不允许执行特殊权限指令,处理器会拒绝执行这条指令。通常来说,这时会将控制权限从user mode切换到kernel mode,当操作系统拿到控制权之后,或许会杀掉进程,因为应用程序执行了不该执行的指令。
User/Kernel mode切换
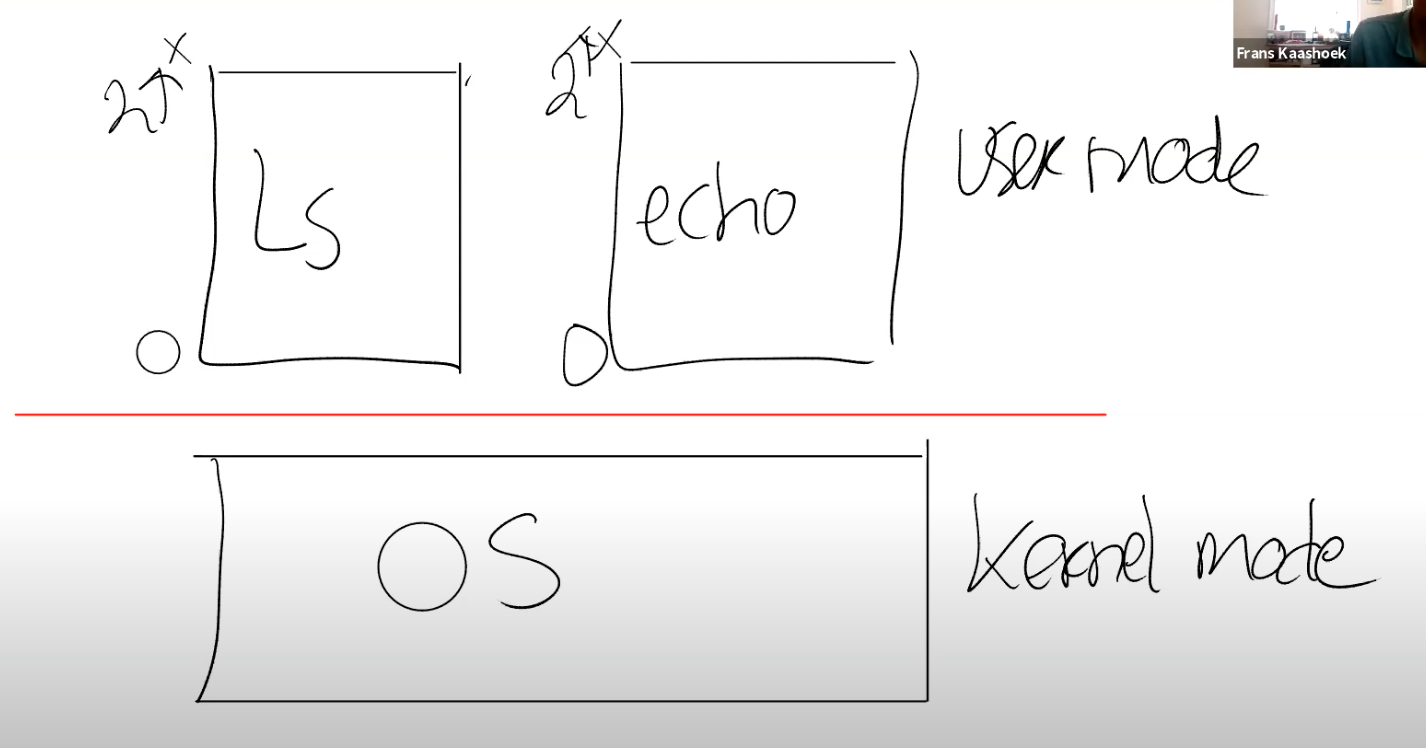
- 当在用户态的应用程序想要调用系统调用时,是如何切换到内核态并执行系统调用呢?
需要有一种方式能够让应用程序可以将控制权转移给内核(Entering Kernel)。
在RISC-V中,有一个专门的指令用来实现这个功能,叫做ECALL。ECALL接收一个数字参数,当一个用户程序想要将程序执行的控制权转移到内核,它只需要执行ECALL指令,并传入一个数字。这里的数字参数代表了应用程序想要调用的System Call。

ECALL会跳转到内核中一个特定,由内核控制的位置。我们可以看到在XV6中存在一个唯一的系统调用接入点,每一次应用程序执行ECALL指令,应用程序都会通过这个接入点进入到内核中。
举个例子,不论是Shell还是其他的应用程序,当它在用户空间执行fork时,它并不是直接调用操作系统中对应的函数,而是调用ECALL指令,并将fork对应的数字作为参数传给ECALL。之后再通过ECALL跳转到内核。
下图中通过一根竖线来区分用户空间和内核空间,左边是用户空间,右边是内核空间。在内核侧,有一个位于syscall.c的函数syscall,每一个从应用程序发起的系统调用都会调用到这个syscall函数,syscall函数会检查ECALL的参数,通过这个参数内核可以知道需要调用的是fork(3.9会有相应的代码跟踪介绍)。
宏内核 vs 微内核 (Monolithic Kernel vs Micro Kernel)
我们可以通过系统调用或者说ECALL指令,将控制权从应用程序转到操作系统中。
之后内核负责实现具体的功能并检查参数以确保不会被一些坏的参数所欺骗。所以内核有时候也被称为****可被信任的计算空间(Trusted Computing Base)TCB
要被称为TCB,内核首先要是正确且没有Bug的。
假设内核中有Bug,攻击者可能会利用那个Bug,并将这个Bug转变成漏洞,这个漏洞使得攻击者可以打破操作系统的隔离性并接管内核。所以内核的 bug越少越好。
- 我们知道用户态和内核态,那什么代码应该在用户态运行,什么代码应该在内核态运行呢?
- 宏内核
其中一个选项是让整个操作系统代码都运行在kernel mode。大多数的Unix操作系统实现都运行在kernel mode。比如,XV6中,所有的操作系统服务都在kernel mode中,这种形式被称为Monolithic Kernel Design(宏内核)。
优缺点分析:
- 首先考虑Bug,这种方式不太好。在一个宏内核中,任何一个操作系统的Bug都有可能成为漏洞。因为我们现在内核中运行了一个巨大的操作系统,有许多行代码运行在内核中,出现Bug的可能性更大了。****所以从安全的角度来说,在内核中有大量的代码是宏内核的缺点。
- 另一方面,一个操作系统,它包含了各种各样的组成部分,比如说文件系统,虚拟内存,进程管理,这些都是操作系统内实现了特定功能的子模块。宏内核的优势在于,因为这些子模块现在都位于同一个程序中,它们可以紧密的集成在一起,这样的集成提供很好的性能。例如Linux,它就有很不错的性能。
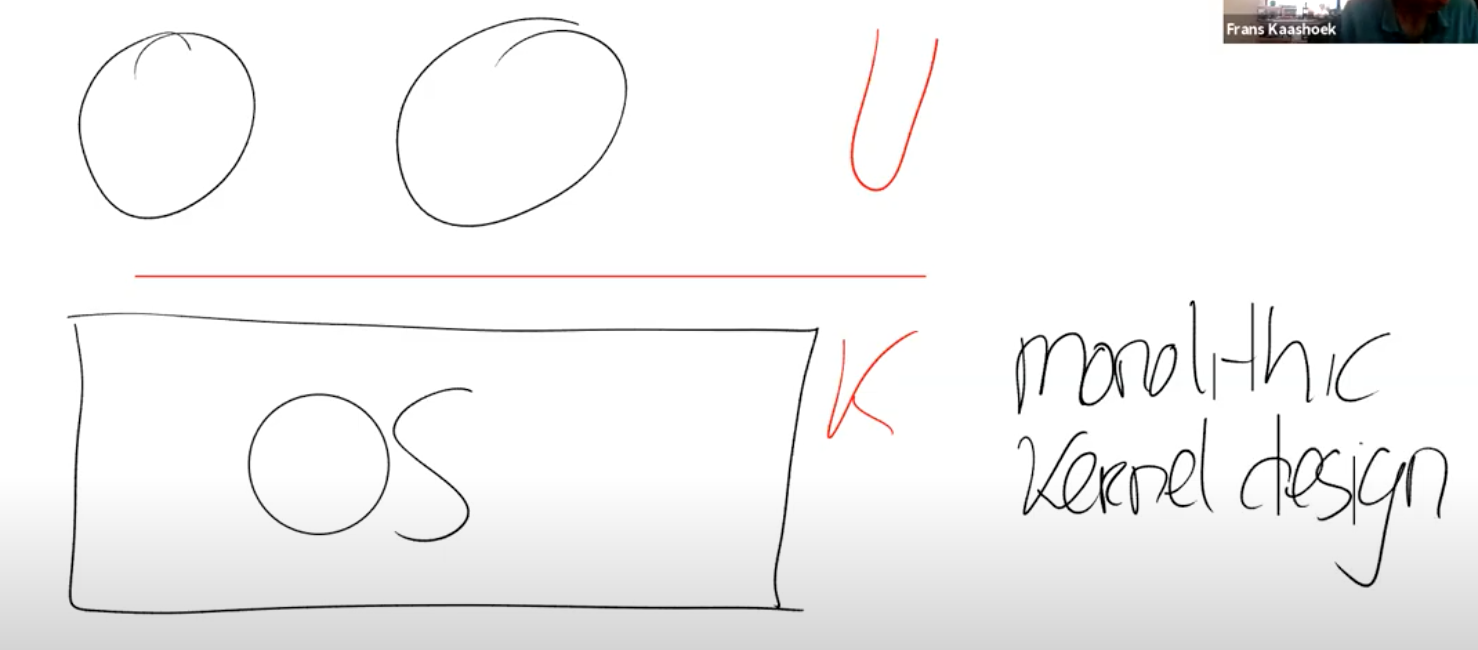
- 微内核
另一种设计主要关注点是减少内核中的代码,它被称为Micro Kernel Design(微内核)。在这种模式下,希望在kernel mode中运行尽可能少的代码。所以这种设计下还是有内核,但是内核只有非常少的几个模块。
微内核的目的在于将大部分的操作系统运行在内核之外。但我们还是会有user mode以及user/kernel mode的边界。
现在,文件系统运行的就像一个普通的用户程序,就像echo,Shell一样,这些程序都运行在用户空间。可能还会有一些其他的用户应用程序,例如虚拟内存系统的一部分也会以一个普通的应用程序的形式运行在user mode。
优缺点分析:
- 某种程度上来说,这是一种好的设计。因为在内核中的代码的数量较小,更少的代码意味着更少的Bug。
- 但当两个文件系统要通信的时候,必须要通过内核进行中转通过消息来实现传统的系统调用****。对于任何文件系统的交互,都需要分别完成2次用户空间<->内核空间的跳转。与宏内核对比,在宏内核中如果一个应用程序需要与文件系统交互,只需要完成1次用户空间<->内核空间的跳转,所以微内核的的跳转是宏内核的两倍。通常微内核的挑战在于性能更差,这里有两个方面需要考虑:
- 在user/kernel mode反复跳转带来的性能损耗。
- 在一个类似宏内核的紧耦合系统,各个组成部分,例如文件系统和虚拟内存系统,可以很容易的共享page cache。而在微内核中,每个部分之间都很好的隔离开了,这种共享更难实现。进而导致更难在微内核中得到更高的性能。