
Lec10:Multiprocessors and locking (Frans)
为什么需要锁?
什么是并发?
大多数内核(如xv6)通过交错执行多个进程来运行。这种交错可能来自多处理器系统,其中多个CPU共享同一物理内存,并且同时访问和修改数据结构,这可能导致数据损坏或不一致。即使在单个处理器上,内核也会切换不同的线程,导致执行交错。此外,不当时间发生的中断也可能干扰数据处理。并发是指由于多处理器、线程切换或中断引起的多个指令流交错执行的现象。
并发控制
内核设计追求高并发以提升性能和响应速度,但这也要求确保数据访问的正确性。为此,设计者采用多种并发控制技术来管理对共享资源的访问。
Xv6及实际操作系统中常用的技术之一是锁,它通过互斥机制保证同一时间只有一个处理器能访问特定的数据。
虽然锁易于理解和实现,但它可能降低系统性能,因为它将并行操作变为串行执行。
竞争条件
竞争条件(race conditions)是指并发访问某个内存位置,且至少有一次访问是写操作。竞争通常是错误的标志,
- 丢失了更新(如果访问是写的);
- 读取了未完全更新的数据结构。
竞争的结果取决于所涉及的两个cpu的确切时间,以及内存系统如何对它们的内存操作进行排序,这可能使竞争引起的错误难以重现和调试。
临界区
锁的互斥效果可以避免数据竞争,在获取/释放锁之间的代码也被称为临界区(critical section)。以下为使用一个锁的示例。
struct element *list = 0;
struct lock listlock;
void
push(int data)
{
struct element *l;
l = malloc(sizeof *l);
l->data = data;
acquire(&listlock);
l->next = list;
list = l;
release(&listlock);
}
当我们说锁保护数据时,指的是锁能够确保某些数据属性(即不变性)在操作过程中得到保持。
这实际上是为了保证数据的一致性,确保某些对数据的操作可以原子性地完成,即要么全部执行成功,要么完全不执行。
使用锁机制可以帮助实现这一目标,因为它可以防止其他并发操作在关键步骤中干扰当前操作。
锁的特性和死锁
基本原则
使用锁的难点在于决定使用多少锁,以及每个锁应该保护哪些数据和不变性。有一些基本原则。
- 当一个CPU可以写入一个变量,而另一个CPU可以读取或写入它时,应该使用一个锁来防止两个操作重叠。这是使用锁的场景。
- 其次,记住锁保护不变量:如果一个不变量涉及多个内存位置,通常需要使用一个锁来保护所有这些位置,以确保维护不变量。
粗粒度或细粒度 coarse-grained or fine-grained
选择使用粗粒度还是细粒度的锁,需根据实际情况决定。
例如,在xv6内核中,只有一个free list锁,当多个CPU上的进程同时尝试分配页面时,每个进程都必须通过自旋等待该锁,这会降低性能。
为解决此问题,可以设计成多个free list,每个都有独立的锁,以支持真正的并行分配,从而提升效率。
对于文件操作,xv6给每个文件设置了一个单独的锁,这样对不同文件的操作可以并发进行。若希望进一步实现对同一文件不同部分的同时写入,则需要采用更细粒度的锁策略。
总之,锁粒度的选择应该基于性能测试结果与系统复杂性的平衡考量。一切都是权衡的结果。
原子指令
- 为了确保锁获取过程的原子性,必须使用原子指令来请求锁。如果采用先读后写的非原子操作,则可能引发数据竞争问题。
为解决此类问题并实现正确的锁机制,存在多种方法,其中最为常见的一种是依赖特定的硬件指令以确保test-and-set操作的原子性。
在RISC-V架构中,这种特定指令被称为amoswap(原子内存交换)。
该指令接受三个参数:目标地址、寄存器r1和寄存器r2。其执行流程如下:首先锁定指定地址,并将该地址处的数据临时存储于一个变量中;随后,将r1中的值写入该地址;接着,将之前暂存的数据写回至r2;最后,解除对该地址的锁定。通过这种方式,amoswap保证了整个操作序列的不可分割性,从而避免了潜在的竞争条件。
**通过加锁机制,可以确保address中的数据被安全地转移到r2,同时r1的数据被存入address,整个过程是原子性的。大多数处理器都支持这种硬件级别的锁定操作,因为它是一种实现锁的简便方法。这里我们把软件锁转换成了硬件锁来保证操作的原子性。
**不同处理器对这一功能的具体实现方式可能有所不同,但通常都遵循以下几种模式:
- 当多个处理器共享同一个内存控制器时,该控制器可以锁定特定地址,允许一个处理器执行几个指令后解锁。由于所有处理器都需要通过这个控制器访问内存,它能够控制操作顺序并实施锁定。
- 如果内存连接在共享总线上,则需要总线控制器以原子方式处理多步内存操作。
- 对于带有缓存的处理器,缓存一致性协议会保证只有一个处理器能够写入待更新的数据行,并对该行进行锁定直到完成更新。
总的来说,尽管具体实现细节各异,但基本思路都是先锁定目标地址、读取现有值、写入新值,最后释放锁(从而实现原子交换)。
C代码中的 portable C library 的 __sync_lock_test_and_set 在 RISC-V 架构下将被编译为 amoswap 指令。
RISC-V 提供了 AMO 系列指令,支持 SWAP, ADD, AND, OR, XOR, MAX, MIN 。*
acquire 中的使用 amoswap.w.aq 指令,原子性地交换内存与寄存器的内容。其他指令集类似的原子 swap 与 CAS (compare and swap) 指令。
risc-v 指令描述 spin 过程如下,
li t0, 1 # Initialize swap value.
again:
amoswap.w.aq t0, t0, (a0) # Attempt to acquire lock.
bnez t0, again # Retry if held.
# ...
# Critical section.
# ...
amoswap.w.rl x0, x0, (a0) # Release lock by storing 0.
指令重排和内存排序-使用内存屏障
指令重排是常用的优化手段。编译器和cpu在重新排序指令时遵循规则,以确保不会改变正确编写的串行代码的结果。然而,规则允许重新排序改变并发代码的结果。这很容易导致多处理器上的错误行为。CPU的排序规则被称为 memory model 内存模型。
1 l = malloc(sizeof *l);
2 l->data = data;
3 acquire(&listlock);
4 l->next = list;
5 list = l;
6 release(&listlock);
如上代码,行 4 与行 6 重排,必然引发并发错误。
xv6使用 __sync_synchronize 指示 memory barrier 内存屏障,防止屏障前后的代码重排,这可以确定绝大部分情况的指令顺序(有些例外在下一章节教授)。对应的 RISC-V 指令是 **fence** 。
死锁和锁获取顺序
死锁其四个必要条件:
- 互斥
- 请求并保持
- 不可剥夺
- 循环等待
为了避免死锁,需要破坏必要条件。锁与其保护的资源天然互斥,这个条件不用改,
- 破坏”请求与保持”:两个思路,静态分配,每个进程在开始执行时就申请他所需要的全部资源;动态分配,每个进程在申请所需要的资源时他本身不占用系统资源。
- 破坏”不可剥夺”:一个进程不能获得所需要的全部资源时便处于等待状态,等待期间他占有的资源将被隐式的释放重新加入到系统的资源列表中,可以被其他的进程使用,而等待的进程只有重新获得自己原有的资源以及新申请的资源才可以重新启动执行。
- 破坏”循环等待”:采用资源有序分配。其基本思想是将系统中的所有资源顺序编号,将紧缺的,稀少的采用较大的编号,在申请资源时必须按照编号的顺序进行,一个进程只有获得较小编号的进程才能申请较大编号的进程。
锁获取顺序
所谓 lock ordering 就是为了防止循环等待。
所有进程采取相同的锁顺序。有相同顺序意味着锁是每个函数规范的组成部分:调用方caller其调用函数的方式必须使锁顺序。
但有时候 锁的顺序与逻辑程序结构冲突,
例如,代码模块M1调用模块M2,但是锁的顺序要求M2的锁必须在M1的锁之前获得。
有时,锁的标识不能提前知道,这可能是因为必须持有一个锁才能发现下一个要获取的锁的标识。这种情况会在文件系统中出现,因为它在一个路径中查找连续的单元;在 wait 和 exit 系统调用代码中出现,因为它们需要在进程表中查找子进程。
中断导致死锁
XV6 使用自旋锁来保护被线程和中断处理程序共享的数据。例
如,clockintr 中断处理程序会增加 tick 计数,而 sys_sleep 会读取这个计数。为了防止冲突,使用了 tickslock 锁来同步这两个操作。
然而,如果一个线程(如 sys_sleep)在持有 tickslock 的同时被中断(比如 clockintr),并且该中断尝试获取相同的锁,就会导致死锁,因为中断不会释放直到锁被解锁,但锁的持有者又因中断而暂停执行。
为了避免这种问题,XV6 规定,在任何CPU获取自旋锁时都必须禁用本地中断,确保不会出现上述情况下的中断打断。只有当锁被释放后,才会重新启用中断。这
简而言之,XV6通过禁用中断保证了自旋锁的安全使用,避免了由于中断导致的潜在死锁问题。对于更复杂的锁行为(如重入),则需要进一步修改系统的设计。
Code: Locks
关于锁的实现,xv6有 spin lock 自旋锁与 sleep lock 睡眠锁两种。这里直接贴 spin lock 的结构与 acquire/release 代码。详细说明,
// in kernel/spinlock.h
// Mutual exclusion lock.
struct spinlock {
uint locked; // Is the lock held?
// For debugging:
char *name; // Name of lock.
struct cpu *cpu; // The cpu holding the lock.
};
// in kernel/spinlock.c
// Acquire the lock.
// Loops (spins) until the lock is acquired.
void
acquire(struct spinlock *lk)
{
push_off(); // disable interrupts to avoid deadlock.
if(holding(lk))
panic("acquire");
// On RISC-V, sync_lock_test_and_set turns into an atomic swap:
// a5 = 1
// s1 = &lk->locked
// amoswap.w.aq a5, a5, (s1)
while(__sync_lock_test_and_set(&lk->locked, 1) != 0)
;
// Tell the C compiler and the processor to not move loads or stores
// past this point, to ensure that the critical section's memory
// references happen strictly after the lock is acquired.
// On RISC-V, this emits a fence instruction.
__sync_synchronize();
// Record info about lock acquisition for holding() and debugging.
lk->cpu = mycpu();
}
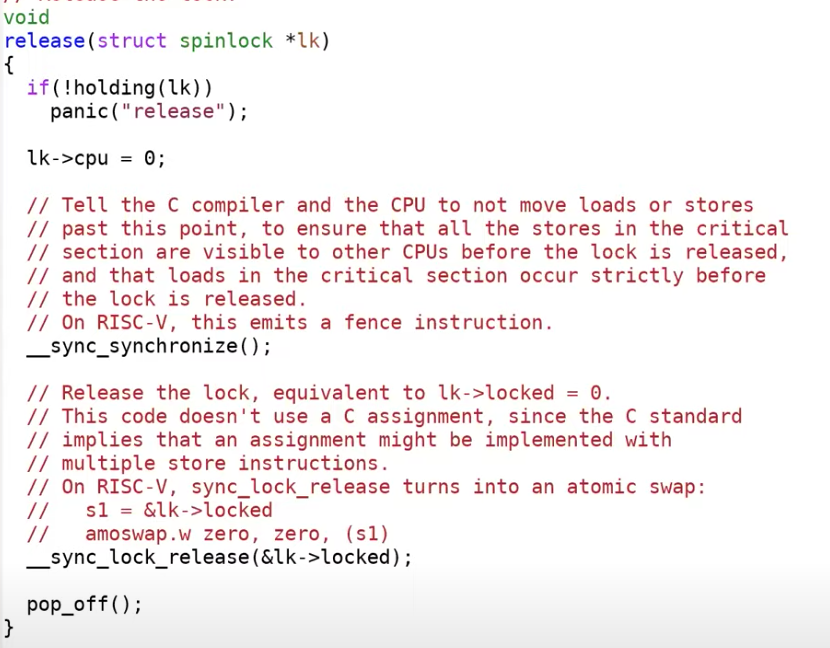
// Release the lock.
void
release(struct spinlock *lk)
{
if(!holding(lk))
panic("release");
lk->cpu = 0;
// Tell the C compiler and the CPU to not move loads or stores
// past this point, to ensure that all the stores in the critical
// section are visible to other CPUs before the lock is released,
// and that loads in the critical section occur strictly before
// the lock is released.
// On RISC-V, this emits a fence instruction.
__sync_synchronize();
// Release the lock, equivalent to lk->locked = 0.
// This code doesn't use a C assignment, since the C standard
// implies that an assignment might be implemented with
// multiple store instructions.
// On RISC-V, sync_lock_release turns into an atomic swap:
// s1 = &lk->locked
// amoswap.w zero, zero, (s1)
__sync_lock_release(&lk->locked);
pop_off();
}
这里仅解释 acquire 的过程, release 完全是相反操作,
- 关闭中断
- 检查重入
- spin 获取锁
- 通过 fence 指令使临界区指令不可重排
- 记录 cpu 信息方便 debug
这里 2 与 5 就不赘述了。重点从另外三个角度讲 spin lock 的细节。
Sleep locks
有时xv6需要长时间持有一个锁。例如,文件系统(第8章)在读取和写入磁盘上的内容时将文件锁定,这些磁盘操作可能需要几十毫秒。如果另一个进程想要获取自旋锁,那么长时间持有自旋锁会导致浪费时间片,因为获取自旋锁的进程会在 spin 过程中浪费很长时间的CPU(可重入虽然被切换,还是会消耗时间片;不可重入禁用中断,由于不切上下文更是一直消耗时间片)。
自旋锁的另一个缺点是,进程不能在保留自旋锁的情况下让出CPU;我们希望这样做,以便其他进程可以使用CPU,而带锁的进程等待磁盘。在持有自旋锁时让出CPU是非法的,
- 因为如果第二个线程试图获取这个自旋锁,导致死锁。第二个线程的 spin 可能会阻止第一个线程运行并释放锁。
- 在持有锁时让出 CPU 也会违反在持有自旋锁时中断必须关闭的要求(禁止锁重入情形下如此)。
因此,我们需要一种锁,它在等待获取时让出CPU,同时在锁被持时也可以让出CPU(和产生中断)。
总结
如果仅从开发人员用锁的角度看,
- 如果不需要共享,尽量就不共享。减少数据竞争可能。
- 可以从粗粒度锁开始设计。
- 究竟粒度粗细与 spin/sleep 选择,都需要测量(measure)。Don’t assume, measure!
- 仅在需要更多并行性时插入细粒度的锁。
- 使用自动化工具如 race detectors 以寻找锁相关的 bugs
本课还详细教授了自旋锁的实现,主要就是三类重点:
- 禁止中断/允许锁重入,如何写嵌套禁止/重入计数
- spin 使用原子指令
- 通过 fence 指令使临界区指令不可重排
本质上锁的一切都是为了互斥但不死锁,同时兼顾设计上的粒度与代码的执行效率。