
内存虚拟化
基本经历了影子页表—> 两阶段页表(硬件翻译)的过程
影子页表
核心思想:Hypervisor 使用一个“假的”页表(影子页表)。
影子页表原理
参考 https://zhuanlan.zhihu.com/p/529084234
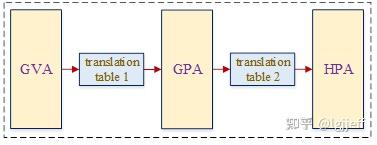
即guest os建立的GVA—>GPA页表在页表基地址寄存器中被hypervisor用shadow页表替换掉。Shadow页表的建立过程比较复杂,以下为其简单原理:
(1)hypervisor为每个vm中的每个进程都维护一张合并了GVA—>GPA和GPA—>HPA两级页表关系的shadow页表。当guest os执行页表切换操作时,hypervisor将截获该操作,并用这张合并后的页表替换掉guest os本身的页表。它就像影子一样覆盖掉了guest os的页表,因此其被称为影子页表
(2)guest os在自身页表中建立GVA到GPA的映射关系
(3)当guest os通过GVA访问内存时,若该GVA在shadow页表中已建立,则可正常通过MMU访问内存,否则会引起缺页异常
(4)由于hypervisor在页表替换时知道被替换guest os页表的基地址,因此在缺页异常处理流程中可通过遍历其对应的页表,查询GVA对应的GPA
(5)GPA是在虚拟机初始化内存条时设置,并与一段host中的用户态虚拟地址HVA绑定,因此hypervisor可以通过GPA获取其对应的HVA
(6)此时可通过host内存管理模块的HVA获取到其对应的HPA
(7)最后对以上流程进行合并,计算得到GVA—>HPA之间的关系,并将其填到影子页表中
性能分析
对于 guest os 的有关页表的操作,主要对于 Guest OS 页的修改,消耗巨大,需要 VM-EXIT 退出到 kvm 中进行修改。
| 内存类型 | Guest OS 在其页表中的意图 | KVM 在影子页表中的设置 | 目的 |
|---|---|---|---|
| 应用程序数据页 (Data) | 可读可写 | 可读可写 | 尊重 Guest,保证性能 |
| 应用程序代码页 (Code) | 只读可执行 | 只读可执行 | 尊重 Guest,保证性能 |
| Guest OS 页表页 | 可读可写 | 只读 | 故意降级,设置陷阱以拦截页表修改 |
| 写时复制 (CoW) 页 | 只读 | 只读 | 尊重 Guest,并将相应的 Fault 反射回去 |
两阶段页表
为了提升影子页表的的性能,硬件对于虚拟化进行了扩展
不同架构的两阶段页表技术对比
| 核心技术点 | Intel (x86) | AMD (x86) | ARM64 (AArch64) | RISC-V |
|---|---|---|---|---|
| 整体虚拟化技术 | Intel VT-x | AMD-V (SVM) | ARM Virtualization Extensions | ’H’ Extension (Hypervisor) |
| 内存虚拟化功能名称 | EPT (Extended Page Tables) | NPT (Nested Page Tables) / RVI | Stage 2 Translation | Two-Stage Address Translation |
| Hypervisor 运行模式 | VMX Root Operation | Host Mode | EL2 (Exception Level 2) | HS-Mode (Hypervisor-extended) |
| Guest OS 运行模式 | VMX Non-Root Operation | Guest Mode | EL1 (Exception Level 1) | VS-Mode (Virtual Supervisor) |
| Stage 1 页表基址寄存器 (Guest OS 使用) | CR3 | CR3 | TTBR0_EL1 / TTBR1_EL1 | vsatp (Guest 视角) |
| Stage 2 页表基址寄存器 (Hypervisor 设置) | EPTP (在 VMCS 中) | nCR3 (在 VMCB 中) | VTTBR_EL2 | hgatp |
| 硬件功能启用方式 | 在 VMCS 中设置 “Enable EPT” 位 | 在 VMCB 中设置 “Enable NPT” 位 | 在 HCR_EL2 中设置 VM 位 | 在 hstatus 等寄存器中设置 |
| TLB 效率优化 (标签) | VPID (Virtual Processor ID) | ASID (Address Space ID) | VMID + ASID | VMID + ASID |
| I/O 虚拟化 (IOMMU) | Intel VT-d | AMD-Vi | SMMU (System MMU) | RISC-V IOMMU (标准制定中) |
翻译过程
在 ARM64 下启用 Stage2 翻译。
假设虚拟机里的一个应用程序(在 EL0)要访问一个内存地址 (GVA):
- CPU 处于 EL0: 准备执行指令。
- 选择页表 (硬件自动): CPU 发现 GVA 是一个低地址(用户空间地址),于是它会自动选择使用
TTBR0_EL1寄存器。 - 第一阶段翻译 (Stage 1: GVA -> GPA):
- CPU 从
TTBR0_EL1中获取 Guest OS 设置的页表基地址。 - MMU 硬件开始遍历这套由 Guest OS 控制的页表,最终将 GVA 翻译成客户机物理地址 (GPA)。
- CPU 从
- 第二阶段翻译 (Stage 2: GPA -> HPA):
- MMU 硬件并不会停下,而是立刻拿着上一步得到的 GPA。
- 它从
VTTBR_EL2寄存器(这个寄存器由在 EL2 的 KVM 控制)中获取 Stage 2 页表的基地址。 - MMU 硬件继续遍历这套由 KVM 控制的页表,最终将 GPA 翻译成真正的宿主机物理地址 (HPA)。
- 访问内存: CPU 最终带着 HPA 去访问物理内存。
一个表格总结:
| 运行实体 | 所在异常级别 | 使用的页表寄存器 | 负责的翻译阶段 |
|---|---|---|---|
| KVM Hypervisor | EL2 | VTTBR_EL2 | Stage 2 (GPA -> HPA) |
| Guest OS 内核 | EL1 | TTBR1_EL1 | Stage 1 (GVA -> GPA, 内核空间) |
| Guest 应用程序 | EL0 | TTBR0_EL1 | Stage 1 (GVA -> GPA, 用户空间) |
stage2 配置
这里有一个问题:Stage 2 (GPA -> HPA) 这一个翻译阶段,是否需要 VM-EXIT 切换到 EL2 进行翻译呢?
答案是:不需要。Stage 2 的翻译过程完全由硬件(MMU)在后台完成,CPU 核心本身不需要切换到 EL2。
这是硬件虚拟化优势的关键点。必须严格区分“配置规则”和“执行规则”。
- 配置规则 (由软件完成): 必须在 EL2 完成。
- 执行规则 (由硬件完成): CPU 在 EL1/EL0 运行时,硬件自动执行。
| 过程 | 谁来做? | CPU 运行在哪个级别? | 解释 |
|---|---|---|---|
配置 Stage 2 页表和 VTTBR_EL2 | KVM 软件 | EL2 | 这是 Hypervisor 的本职工作,必须在最高权限下设置好内存映射规则。 |
虚拟机执行一条 LDR / STR 指令 | Guest 软件 (App/OS) | EL0 / EL1 | 这是虚拟机在正常运行自己的代码。 |
| 执行完整的 GVA -> HPA 地址翻译 | 硬件 MMU | (CPU 核心仍然在 EL0 / EL1) | 这就是硬件辅助的精髓! MMU 作为一个独立的硬件单元,在后台完成了两阶段的查表工作。CPU 核心并没有改变它的异常级别。 |
| 处理 Stage 2 的翻译失败 (Fault) | KVM 软件 | CPU 从 EL1/EL0 陷入到 EL2 | 这是“例外”情况。只有当硬件无法独立完成翻译时,才需要软件介入。 |
硬件 MMU 将原本由软件模拟的影子页表功能卸载至硬件,使得常规内存访问路径完全在 EL0/EL1 执行,仅在 Stage-2 异常时陷入 EL2,从而规避了影子页表的性能瓶颈。